Security Brief: AI Agent Security & Reporting Transparency
Security Brief: AI Agent Security & Reporting Transparency
- 들어가며
- LLM 이후의 현실: 취약점은 더 빨리 드러난다
- Meta의 Practical AI Agent Security
- Google Project Zero의 Reporting Transparency
- 마무리
들어가며
LLM의 등장이 모든 영역에 변화를 가져오고 있는 와중에 보안 영역에도 분명한 변화를 가져왔습니다.
처음에는 취약점을 찾는 쪽과 방어하는 쪽 모두 LLM을 적극적으로 활용하여 균형이 유지되지 않을까 생각했습니다.
하지만 최근의 흐름을 지켜보며 느낀 점은,
체감상 공격 진영이 LLM에 조금 더 빠르게 적응하고 있는 것처럼 보인다는 것이었습니다.
LLM을 활용하면서 취약점을 찾는 장벽은 낮아졌고,
공격 시도는 더 많아졌으며,
공격 방법은 더 다양해졌고,
무엇보다 최근에는 보면 결과물의 품질 또한 눈에 띄게 좋아지고 있다고 느꼈습니다.
LLM 이후의 현실: 취약점은 더 빨리 드러난다
물론 방어진영에서의 현실적인 제약도 분명히 존재한다고 생각합니다.
LLM을 활용한 최신 보안 프로세스를 충분히 반영하여 생성된 코드가
모든 제품에 빠르게 적용되기에는 여전히 구조적인 한계가 있기 때문입니다.
레거시 코드가 너무 많고,
실제 제품 개발과 배포 과정은 자동화된 이상적인 흐름과는
거리가 있는 경우가 많습니다.
그래서 지금의 상황은 일종의 과도기처럼 보일 수도 있겠다고 느꼈습니다.
하지만 DARPA의 AI Cyber Challenge(AIxCC) 사례를 보면서,
이 변화를 다른 관점에서 다시 보게 되었습니다.
자동화된 시스템이 꽤 높은 정확도로 많은 버그를 찾아내고,
심지어 패치 후보까지 제시하는 모습을 직접 확인하면서,
“완벽한 코드를 만드는 능력”보다
“취약점이 훨씬 더 빠르게 드러나는 환경이 되었다는 사실”이라고
생각하게 되었습니다.
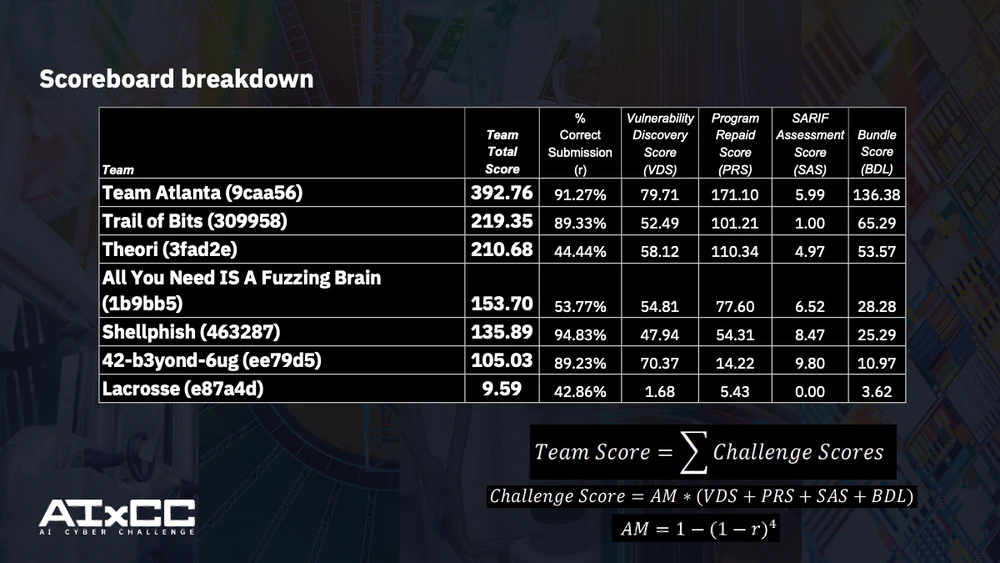
즉, 최근 많은 취약점이 드러나는 현상이 코드 품질이 점점 나빠지고 있다는 것이 아니라,
취약점 발견 속도가 개발·배포·패치 프로세스를 앞질러 가고 있다는 점이라고
생각됩니다.
그래서 이러한 요즘 환경에서는 취약점이 없는 코드를 목표로 삼기보다는,
취약점이 발견되었을 때 얼마나 빠르게 통제하고,
영향을 제한하고,
대응할 수 있는지가 더 중요하다고 생각됩니다.
그래서 점점 “완벽한 코드”, "완벽한 시스템"보다는
현실적인 방어와 대응을 가능하게 하는 프로세스 개선 사항들이
요즘 보안 환경에서 많이 등장하고 있다는 느낌을 받았습니다.
Meta의 Practical Approach to AI Agent Security
이러한 흐름에서 Meta가 공개한
Agents Rule of Two: A Practical Approach to AI Agent Security 글은
상당히 현실적으로 느껴졌습니다.
요즘 회사에서도 업무 편의성과 LLM의 활용을 위해 엄청난 수의 Agent가 개발되고 사용되고 있습니다.
그러나 우후죽순 개발되는 Agent들의 보안에 대한 신경은 그만큼 크게 고려되고 있진 못하는 것 같습니다.
이러한 시점에서 Meta의 글은 유용한 도움이 될 것이라 생각됩니다.
에이전트는 API를 호출하고,
파일을 읽고 쓰며,
외부 시스템과 상호작용하고,
실제 상태 변화를 만들어냅니다.
이 시점에서 발생하는 문제는
단순한 코드 버그의 문제가 아니라,
어떤 행동을 어디까지 허용할 것인가에 대한
정책과 통제의 문제라고 생각했습니다.
Agents Rule of Two
Meta는 이를 설명하면서
“Agents Rule of Two”라는 개념을 제시합니다.
에이전트가 가질 수 있는 위험한 속성은
크게 다음 세 가지로 정리됩니다.
- Process untrustworthy inputs: 신뢰할 수 없는 외부 입력을 처리하는 능력
- Access to sensitive systems or private data: 민감한 데이터나 권한에 접근할 수 있는 능력
- Change state or communicate externally: 외부 시스템에 영향을 주는 행동을 수행하는 능력
Meta의 권고는 명확합니다.
이 세 가지 중,
에이전트에게 동시에 부여되는 것은
최대 두 개까지만 허용해야 한다는 것입니다.
세 가지가 동시에 결합되는 순간,
프롬프트 인젝션이나
의도하지 않은 입력 하나가
곧바로 치명적인 실행 결과로
이어질 수 있기 때문입니다.
원글에서는 다양한 예시와 함께 얘기하고 있어 시간이 있다면 위의 Meta의 글을 읽어보시는 것을 추천드립니다.
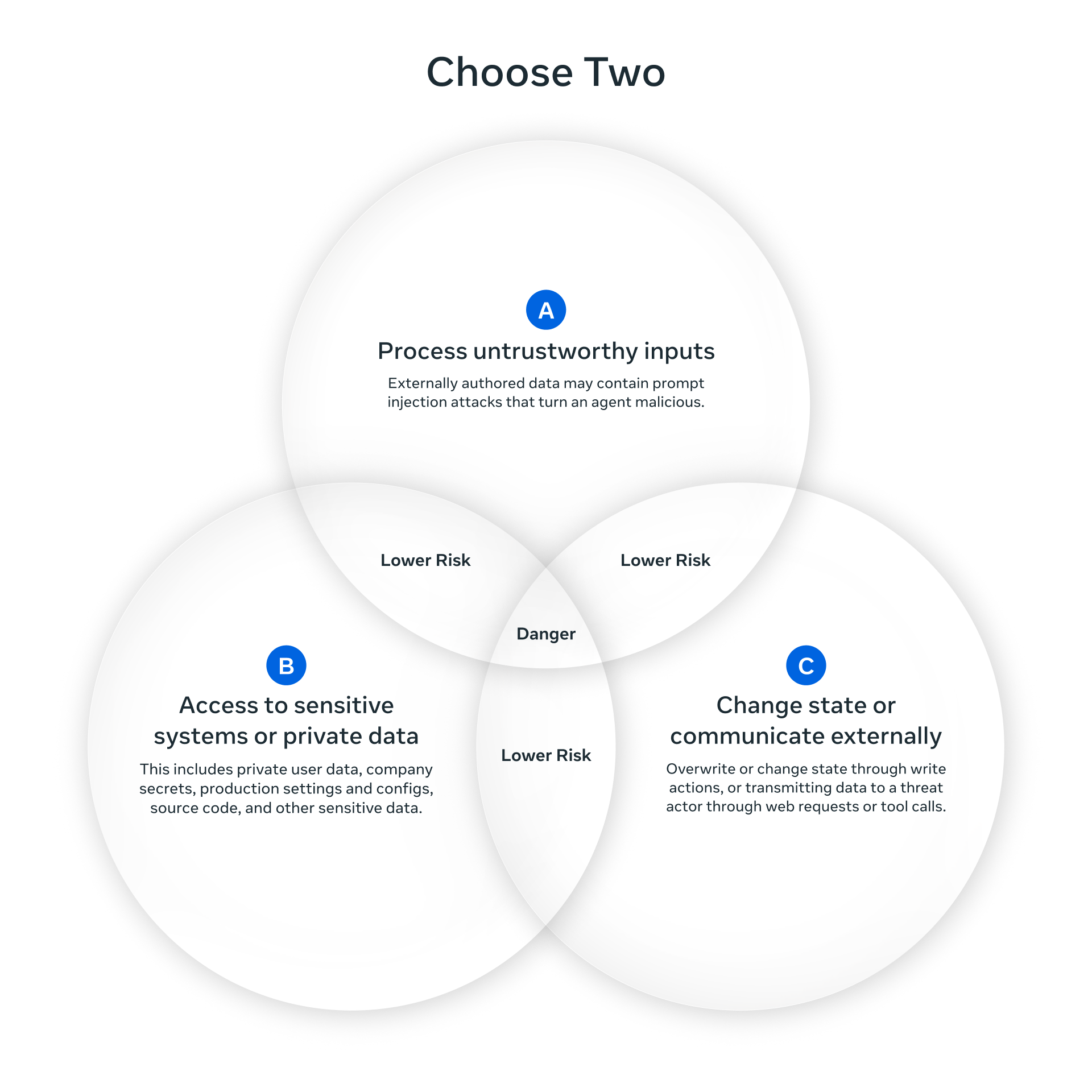
이 접근 방식은 프롬프트 인젝셕은 완전히 막기 위한 노력보다는,
프롬프트 인젝션은 어디서든 발생할 수 있다는 가정하에 에이전트의 행동과 권한을 설계하는
프로세스 보안에 가까워 보였습니다.
Google Project Zero의 Reporting Transparency
한편 Google Project Zero는
또 다른 관점에서, 유사한 문제를 지적하고 있습니다.
올해 7월 말부터 Project Zero 팀은 기존의 90+30 공개 정책은 유지하되,
취약점이 벤더에 제보되었다는 사실 자체를
약 일주일 내에 공개하는
Reporting Transparency를
실험적으로 도입했습니다.
이 정책 변화에서 인상적이었던 점은,
“패치를 언제 공개할 것인가”보다
“취약점이 이미 보고되었다는 사실을
얼마나 빨리 드러낼 것인가”에
초점을 맞췄다는 점입니다.
현실에서는 종종 다음과 같은 상황이 발생합니다.
- 업스트림 벤더는 패치를 준비했지만
- 다운스트림 벤더의 통합이 지연되고
- 그 사이 취약점은 이미 공격자에게 알려진 상태가 됩니다.
이처럼
프로세스의 지연 자체가 공격 표면이 되는 상황에서,
취약점 공개와 패치 반영 속도를
끌어올리기 위한 시도는
앞으로 더욱 중요해질 것이라 생각됩니다.
마무리
Meta의 Practical Approach to AI Agent Security와
Google Project Zero의 Reporting Transparency의
글을 보며 두 글에서의 요즘 보안에 접근하는 방식이
공통적으로 말하고 있는 메시지는
분명하다고 느꼈습니다.
- 완벽한 코드 혹은 시스템은 현실적으로 존재하기 어렵고
- 취약점은 점점 더 빠르게 발견되며
- 결국 통제, 권한, 공개, 배포 일련의 프로세스 자체를 통해 취약점 영향도를 최소화 하겠다는 느낌이 들었습니다.
물론, 코드 보안도 여전히 중요하다고 생각합니다.
하지만 그것만으로
모든 공격을 막을 수 있다고
기대하기는 점점 어려워지고 있습니다.
보안의 방어 측면이 점점
코드 → 정책 → 프로세스 → 운영으로
이동하고 있는 것처럼 보입니다.
물론 이는 앞으로도 계속될 변화의 현 시점만 바라보며 정리해본 하나의 기록이며
앞으로는 완전히 다른 상황이 될수도 있다고 생각됩니다.
다만 최근 여러 글들을 읽으며 제가 느끼게 된 점을 짧지만 간단하게 정리하여 작성해보았습니다.
다음에 기회가 되면 이와 더불어 Zero Trust Security에 대해서도 한번 다뤄보면 좋을 것 같습니다.