libFuzzer: LLVM 기반 Coverage-Guided Fuzzing Tool
libFuzzer: LLVM 기반 Coverage-Guided Fuzzing 툴 소개
- 들어가며..
- LibFuzzer란?
- AFL과의 차이점: In-Process vs Fork-Server
- Coverage와 Input
- FuzzGen(LibFuzzer 드라이버 자동 생성기 도구)
- 마무리
들어가며..
오늘은 AFL과 다른 특징을 가진 Fuzzer인 libFuzzer에 대해서 살펴보도록 하겠습니다. 보통 개발이 어느 정도 진행이 되어 실행 파일이 나와야 수행 가능한 AFL과는 다르게 LibFuzzer는 개발 단계 도중 그리고 Unit Test를 기반으로도 수행이 가능하기 때문에 조금 더 개발 사이클 앞 단에서 수행할 수 있는 Fuzzer입니다. LibFuzzer는 LLVM 프로젝트의 일부로, coverage-guided fuzzing을 지원하는 Fuzzing 도구입니다.
LibFuzzer란?
LibFuzzer는 프로그램에 무작위 입력을 주입하여 충돌이나 예외를 유발하는 in-process fuzzer입니다.
LLVM의 -fsanitize=fuzzer 옵션을 통해 손쉽게 통합할 수 있고,
위에서도 언급하였듯이 단위 함수 수준에서 동작하기 때문에
유닛 테스트 단계부터 퍼징이 가능합니다.
LibFuzzer는 최신 clang 컴파일러에 내장되어 있어 다음과 같이 clang/clang++로 빌드하면 됩니다.
clang++ -fsanitize=fuzzer,address fuzz_target.cpp -o fuzz_me퍼징은 아래의 시그니처를 갖는 함수를 대상으로 작동합니다:
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size);
AFL과는 다르게 독립된 바이너리 대신 테스트 대상 함수에 직접 링크되어 동작하는
in-process fuzzing을 특징으로 합니다.
즉, LibFuzzer는 위의 함수를 동일한 프로세스 내에서 반복 호출하며 퍼징을 진행합니다.
그래서 만약 퍼징 대상 함수가 충돌(crash)하면 프로세스 전체가 종료되며, 이전 상태로 되돌아갈 수 없습니다.
AFL과의 차이점: In-Process vs Fork-Server
여기서 AFL과의 차이점을 살펴보면 아래와 같습니다.
| 항목 | LibFuzzer | AFL |
|---|---|---|
| 실행 방식 | In-process (프로세스 내에서 테스트 함수 호출) | Fork-based (입력마다 새 프로세스 fork) |
| 크래시 처리 | 크래시 시 전체 종료 (재시작 필요) | 크래시 후 부모 프로세스 복구 가능 |
| 속도 | 매우 빠름 (fork overhead 없음) | fork로 인한 오버헤드 존재 |
| 안정성 | 크래시 발생 시 전체 중단 | 크래시 후 자동 복구 및 계속 진행 |
| 테스트 방식 | 함수 단위 유닛 테스트 기반 가능 | 실행 파일 기반 (stdin, 파일 입력) |
그래서 개발단계에서 LibFuzzer를 활용하게 되면 Crash가 발생되면 더 이상 퍼징을 진행할 수 없어 코드를 수정하고 다시 Fuzzer를 수행해야해서 오히려 개발단계에서는 더 좋은 Fuzzing 도구가 될 수 있다고 생각됩니다. 물론, 이 LibFuzzer를 구성하는게 귀찮긴 하겠지만 아래에서 자동으로 LibFuzzer를 구성할 수 있는 페이퍼도 같이 소개해드리도록 하겠습니다.
Coverage와 Input
Coverage
Fuzzer가 사용하는 Coverage는 대표적으로 두 가지 방식이 존재합니다.
- Block Coverage: 어떤 코드 블록(Basic Block)이 실행되었는가?
- Edge Coverage: 어떤 블록에서 어떤 블록으로 이동했는가?
ex)
void foo(int x) {
if (x < 10)
A();
else
B();
C();
}위 코드에서:
- Block Coverage는 A, B, C가 실행됐는지만 확인합니다.
- Edge Coverage는 다음과 같은 흐름을 추적합니다:
Entry → A → CvsEntry → B → C
즉, Block Coverage에서는 A와 B가 모두 실행됐는지를 체크하는 반면, Edge Coverage는 어떤 경로로 C에 도달했는지를 구분합니다.
Input
LibFuzzer의 함수 시그니처는 LLVMFuzzerTestOneInput(const uint8_t *data, size_t size)로 고정되어 있습니다.
그래서 만약 여러 Input을 받는 함수를 대상으로 퍼징을 하려면 data를 잘 분리 혹은 파싱해서 가공해야 합니다.
다양한 방식이 있겠지만 여기서는 실용적인 두 가지 방식인 슬롯 나누기 (수동 파싱)과 코드 내 구조체 기반 Structured Fuzzing을 소개해드리겠습니다.
수동 파싱 (슬롯 나누기 방식)
입력 데이터를 고정된 위치(slot)를 기준으로 해석하여 여러 인자로 나눕니다.
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
if (size < 3) return 0;
uint8_t id = data[0]; // 1바이트
uint8_t flag = data[1]; // 1바이트
uint8_t len = data[2]; // 1바이트
if (size < 3 + len) return 0;
const uint8_t* payload = data + 3;
my_func(id, flag, payload, len);
return 0;
}
- 장점: 퍼저가 각 필드를 독립적으로 mutation할 수 있어 효과적인 분기 탐색 가능
- 단점: payload 길이 검증을 반드시 해야 함
Structured Fuzzing (코드 내 구조체 정의 기반)
구조체를 정의하고, memcpy로 데이터를 바로 구조체에 매핑합니다.
#include <cstdint>
#include <cstring>
struct MyInput {
uint32_t id;
int16_t value;
bool flag;
};
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
if (size < sizeof(MyInput)) return 0;
MyInput input;
memcpy(&input, data, sizeof(MyInput));
my_func(input);
return 0;
}
- 장점: 코드가 깔끔하고 빠름. 퍼저가 각 필드를 의미 있게 mutation할 수 있음
- 주의: 구조체 padding으로 인한 크기 차이에 유의
이러한 방식들을 사용하고 그리고 Coverage 측정이 잘 되게 하려면 기본적으로 유동 길이를 갖는 파라미터는 가장 마지막에 배치하는 것이 좋습니다.
그리고 만약 유동 길이를 가진 파라미터가 두개 이상 될 경우에는 Coverage 측정이 제대로 되지 않을 수 있습니다.
왜냐하면 유동 길이를 가진 파라미터가 두개 이상일 경우 하나의 생성된 Input에 대해서 어느 길이까지를 첫 번쨰 파라미터, 그 이후 길이를 두번째 파라미터로 넣을지도 정하기가 애매하고
이로 인해 만약 처음 생성한 Input에서는 특정 위치의 바이트가 첫 번째 파라미터로 들어가서 Coverage가 측정된 후에
두 번째 생성된 Input에서는 해당 위치의 바이트가 두번째 파라미터로 들어가서 새로운 Path를 타게 되어 Coverage가 증가된 경우
Fuzzer에서는 해당 위치의 바이트가 Path를 결정짓는 유의미한 바이트라고 생각할 수 있지만 막상 실제 프로그램 코드에서는 첫번째 파라미터로 들어가냐
두번째 파라미터로 들어가냐의 차이이기 때문에 Fuzzer와 프로그램 코드 사이의 인식 차이가 발생할 수 있습니다.
그 다음으로는 LibFuzzer를 활용한 자동화 도구를 하나 소개해드리도록 하겠습니다.
FuzzGen(LibFuzzer 드라이버 자동 생성기 도구)
FuzzGen PaperFuzzGen GitHub
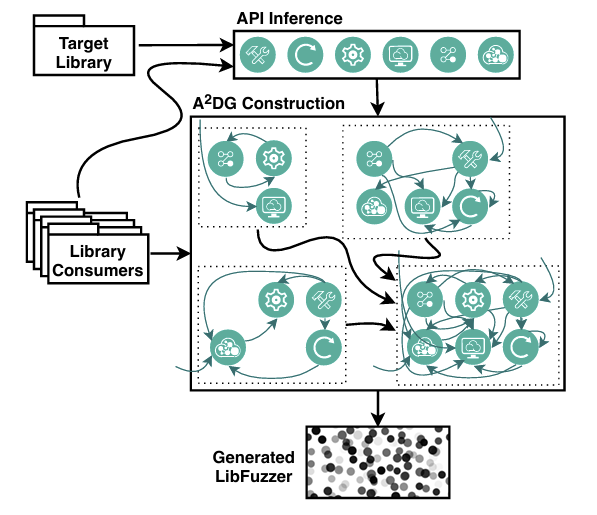
기회가 된다면 나중에 자세히 소개하겠지만 여기서 간단하게만 소개하자면 FuzzGen은
Fuzzing 자동화 도구로 라이브러리를 정적 분석하여 LibFuzzer-Compatible Fuzzing Driver를 자동으로 생성합니다.
즉, 사람이 수동으로 작성해야 했던 LLVMFuzzerTestOneInput() 함수를 코드 분석을 통해 자동 생성해주는 도구입니다.
동작 순서를 간단하게 살펴보면 먼저, 함수 추론을 통해 AADG(Abstract API Dependence Graph)를 생성합니다.
즉, 라이브러리 내부의 함수 호출 관계 및 시퀀스를 Graph로 구성해줍니다.
그 이후 각 함수의 파라미터 타입을 분석하여 Fuzzing 가능한 primitive / pointer 등으로 분리합니다.
최종적으로 위의 정보들을 토대로 적절한 API 조합과 파라미터 초기화 등을 하여 자동으로 LibFuzzer 드라이버를 생성하게 됩니다.
예를 들어 라이브러리의 Test() 같은 API를 퍼징하려면 내부적으로 TestInit(), TestCleanup()
등의 호출 순서를 알아야 제대로 퍼징을 수행할 수 있습니다.
FuzzGen은 이런 API Sequence까지 고려한 Fuzzing Code를 자동으로 생성해줍니다.
마무리
오늘은 LibFuzzer에 대해서 간략하게 정리를 해봤습니다. 실행파일이 없어도 수행할 수 있는 Fuzzer라는 점에서 개발단계에서 미리 개발자분들이 활용할 수 있는 좋은 Fuzzer라는 생각이 들며 물론 보통 개발자분들은 기능을 구현하기에도 바쁘기 때문에 최대한 자동으로 Unit Test기반으로 LibFuzzer Driver가 작성되어 프로세스에 녹아들 수 있으면 정말 좋지 않을까 싶습니다.
Unit Test 기반 Fuzzer는 아래 두 주제를 찾아보시면 좋을 것 같습니다.
UTopic: From Unit Tests to Fuzzing
FuzzBuilder: Automated building greybox fuzzing environment for C/C++ library