AFL Parallel Fuzzing에 대해서
AFL(American Fuzzy Lop) Parallel(병렬) Fuzzing
들어가며..
AFL의 경우 자료도 많고 아시는 분도 많고 해서 오늘은 AFL 중에서 Parallel Fuzzing에 대해서만 간단하게 알아보도록 하겠습니다.
먼저 Parallel Fuzzing의 경우 Main Node와
Secondary Instance가 존재합니다.
※ 과거에는 Master Instance, Slave Instance 용어를 사용했지만
요즘은 포용성 이슈 때문에 Main, Secondary 혹은
Primary, Secondary 용어를 사용하는데
AFL의 경우 -M, -S 명령어를 동일하게 사용할 수 있는 Main Node,
Secondary Instance 용어를 사용하는 것 같습니다.
Main Node의 경우 Deterministic Stage를 수행하며
Secondary Instance의 경우 Deterministic Stage를
수행하지 않는 것이 둘의 차이점입니다.
Deterministic Stage를 수행하고 안하고의 차이를 알려면
먼저 Mutation 과정을 알아야합니다.
※ Mutation Stage: Fuzzer에서 입력 데이터를 변형(Mutate)하는 단계로
Fuzzer가 기존에 수집한 입력(seed corpus)를 조금씩 바꿔서 새로운 Test Case를
만들어 내는 작업입니다.
Mutation Stages
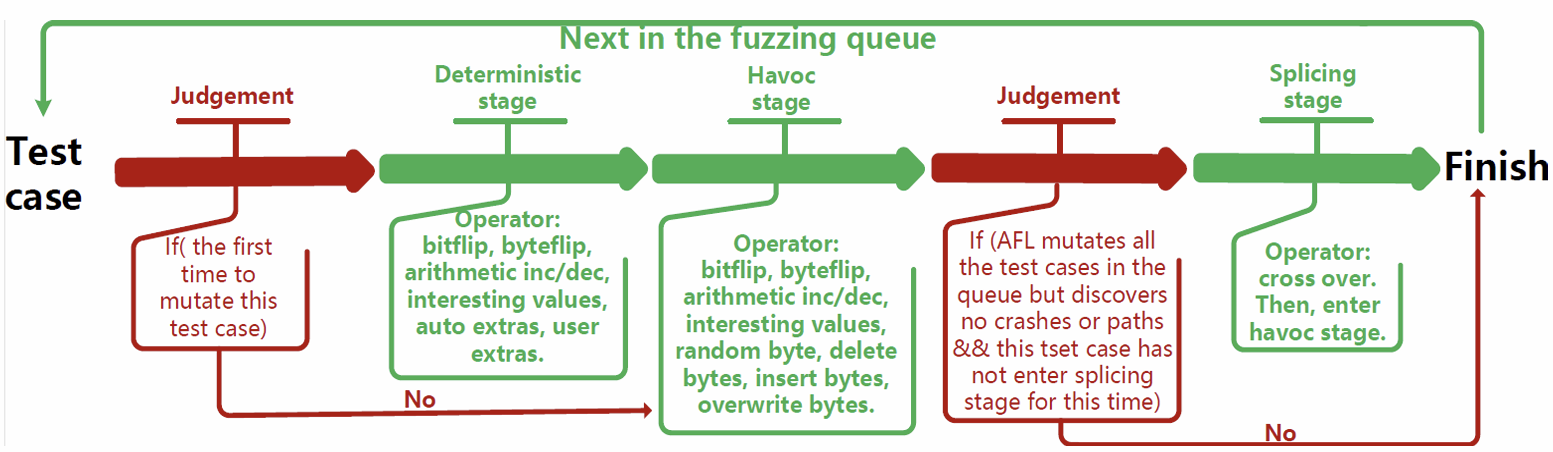
아래에서 자세히 설명하겠지만 그 전에 간단하게 각 Stage를 설명하면 아래와 같습니다.
- Deterministic Stage: 입력을 체계적으로 조금씩 바꿔보는 단계
- Havoc Stage: 무작위로 큰 변화나 여러 Mutation을 한번에 적용
- Splicing Stage: 두 개의 입력을 splice(합성)해서 새로운 입력 생성
Single Fuzzing을 기준으로 Mutation 순서를 보면
- 먼저 Input이 처음 Mutation 과정을 수행하게 되면 우선 먼저 Deterministic Mutation을 수행하게 됩니다.
- Deterministic Stage가 끝나면 Havoc Stage로 넘어갑니다.
- Havoc Stage가 끝난 후 새로운 Coverage가 없거나 Crash가 발생하지 않았으며 Splicing Stage를 진행한 적 없으면 Splicing Stage로 넘어갑니다.
- 그 이후 다시 Havoc Stage로 넘어갑니다. 만약 새로운 Coverage를 발견 혹은 Crash가 발생하였거나 Splicing Stage를 이미 진행한 적이 있다면 Fuzzing Queue에서 다음 Test Case Input로 넘어가게 됩니다.
이를 통해 AFL Mutation의 전략을 대략적으로 살펴보면 체계적인 과정을 통해 소규모로 변경하며 탐색(Deterministic) 이후 무작위 대규모 변경(Havoc) 만약 실패 시 다른 입력과 조합하여 큰 변화를 시도(Splicing)하는 식으로 볼 수 있습니다.
위의 그림을 보면 사실 Deterministic Stage와 Havoc Stage의 Operator가 비슷한 것을 확인할 수 있습니다.
그런데도 둘이 무슨 차이가 있느냐 라고 본다면 기본적으로 어디를 어떻게 바꾸느냐 의 차이가 있습니다.
Deterministic Stage의 경우 순차적이고 체계적으로 즉, bit/byte 를 처음부터 끝까지 한칸씩 도면서 모두 실험을 해보게 됩니다. 그리고 고정된 순서로 Operator가 진행이 되며 이를 통해 특정 바이트가 중요한지 체계적으로 탐색하는 과정이라고 생각을 하면 됩니다.
반면 Havoc Stage의 경우 랜덤한 위치(임의 Offset)에 대해서 작은 연산부터 큰 블록에 해당하는 Mutation까지 혼합해서 진행하여 Operator 순서도 매 Iteration마다 랜덤으로 조합하여 진행하게 됩니다. 즉, 랜덤으로 얻어 걸리길 바라며 새로운 경로를 트리거해보는 시도라고 볼 수 있습니다.
그래서 보통 Deterministic Stage가 오래 걸리고 Havoc Stage가 비교적 빨리 끝나는 경향이 있습니다.
AFL Parallel Fuzzing
그럼 다시 Parallel Fuzzing으로 돌아오도록 하겠습니다.
위에서 살펴봤듯이 Main Node와 Secondary Instance의 차이는 Main Node의 경우 Deterministic Stage를 수행하고 Secondary Instance의 경우 Deterministic Stage를 수행하지 않고 바로 Havoc Stage부터 수행하는 차이가 있습니다.
이 차이점을 알고 AFL Parallel Fuzzing 구성 방법을 살펴보면 보통 아래와 같이 총 3개의 케이스가 있는것을 알 수 있습니다. (Core의 개수가 n개일 경우)
- 1개의 Main Node + (n-1)개의 Secondary Instance
- n개의 Main Node
- n개의 Secondary Instance
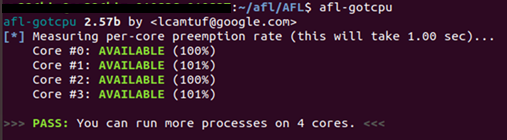
먼저 그 전에 Core 개수를 파악할 수 있는 afl 명령어는 afl-gotcpu입니다.
1개의 Main Node와 n-1개의 Secondary Instance
Run the first one ("main node", -M) like this:
./afl-fuzz -i testcase_dir -o sync_dir -M fuzzer01 [...other stuff...]
…and then, start up secondary (-S) instances like this:
./afl-fuzz -i testcase_dir -o sync_dir -S fuzzer02 [...other stuff...]
./afl-fuzz -i testcase_dir -o sync_dir -S fuzzer03 [...other stuff...]
Single Fuzzer

Parallel Fuzzer
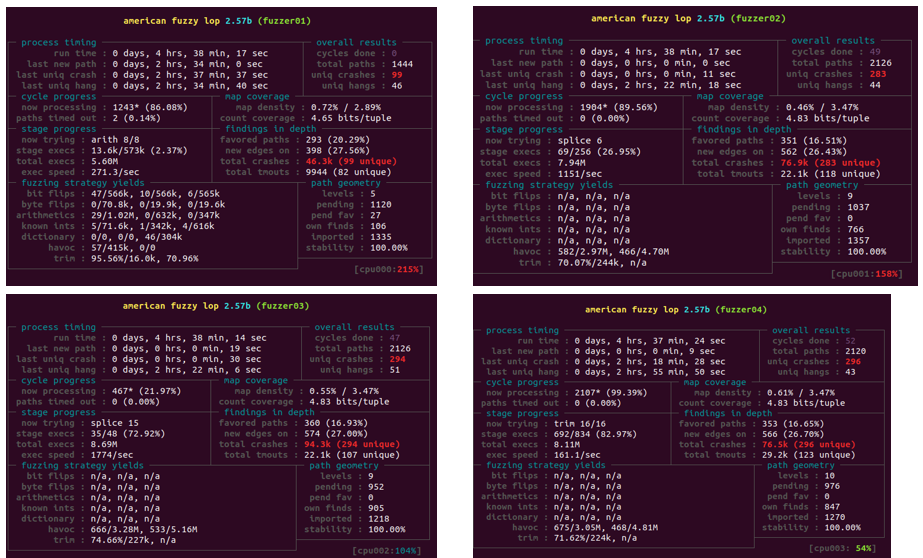
아래 화면에서 보듯이 fuzzer마다 output directory를 따로 가지고 있는것을 볼 수 있습니다.

Paraller Fuzzer - fuzzer01

가장 정석적인 방법이라고 생각될 수 있습니다.
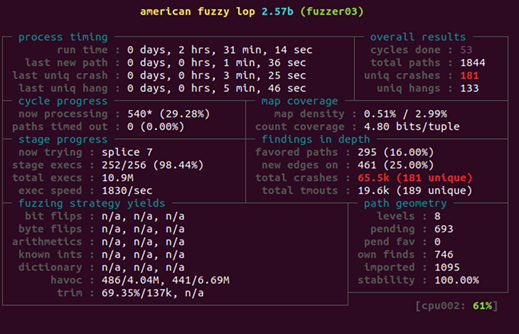
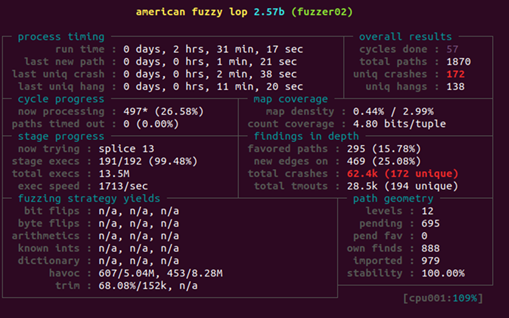
아래와 같이 Parallel Fuzzer State를 살펴보면
위에서 언급했듯이 Main Node의 경우 Deterministic Stage를
수행하기 때문에 fuzzer01의 경우 다른 Secondary Instance Fuzzer들에 비해
확실히 path geometry의 level이 낮은 것을 확인할 수 있습니다.
main node fuzzer: level 5
secondary instance fuzzer: level 9~10
※ 나중에 기회가 되면 해당 UI의 의미들도 살펴보도록 하겠습니다.
참고로 Stability의 경우 동일한 입력에 대해서 동일한 Coverage bitmap이 나오는지를
나타내는 지표로 만약 AFL Proxy등을 이용하여 직접 Fuzzing환경을 구성하여 AFL을 붙인 경우
stability 지표가 제대로 Fuzzing이 수행되는지 확인할 수 있는 많은 도움이 됩니다.
n개의 Main Node
보통 Main Node를 여러 개 두는 것은 추천하지 않습니다!
Note that you must always have one -M main instance! Running multiple -M instances is wasteful!
There is support for parallelizing the deterministic checks. This is only needed where
many new paths are found fast over a long time and it looks unlikely that main node will ever catch up, and
deterministic fuzzing is actively helping path discovery (you can see this in the main node for the first for lines in the “fuzzing strategy yields” section. If the ration found/attemps is high, then it is effective. It most commonly isn’t.)
Only if both are true it is beneficial to have more than one main. You can leverage this by creating -M instances like so:
./afl-fuzz -i testcase_dir -o sync_dir -M mainA:1/3 [...]
./afl-fuzz -i testcase_dir -o sync_dir -M mainB:2/3 [...]
./afl-fuzz -i testcase_dir -o sync_dir -M mainC:3/3 [...]
위에서 설명한대로 Main Node Fuzzer를 여러 개 두는 것을 추천하진 않지만 만약
1. 새로운 경로가 빠르고 오랜 시간동안 다수 발견되어 Main Node가 이를 따라잡기 어려워 보이는 경우
2. Deterministic Fuzzing이 실질적으로 경로 탐색에 도움이되는 경우
(대체로 그렇지 않은 경우가 많음.)
에 사용할 수 있는 기법입니다.
n개의 Secondary Instance
매우 느리고 복잡한 Target을 fuzzing할 경우 오히려 더 효과적
매우 느리고 복잡한 Target을 퍼징해야 될 경우 보통 Deterministic Stage가 효과적이지 않을 수 있습니다. 그래서 이 경우 오히려 Deterministic Stage를 거치지 않고 Havoc Stage를 통해 랜덤성에만 기반하여 빠르게 여러 Input을 테스트해보는 것이 더 효과적일 수 있습니다.
Sync Fuzzers
마지막으로 Parallel Fuzzing을 수행할 경우 각 Fuzzer들이 어떻게 Sync를 맞추는지 살펴보고 마무리 하도록 하겠습니다.
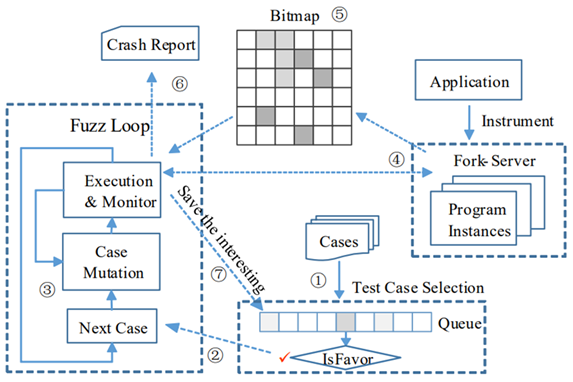
먼저 간단하게 설명드리면 AFL의 동기화 방식은 파일 시스템 기반으로 동작합니다.
[ Node1 queue ] <---> [ Node2 queue ] <---> [ Node3 queue ]
각 노드:
1) 자기 queue 돌리기
2) 다른 노드 queue에서 새 input 가져오기
3) 가져온 input도 mutation stage 돌리기
코드를 간략하게 살펴보면 아래와 같습니다.
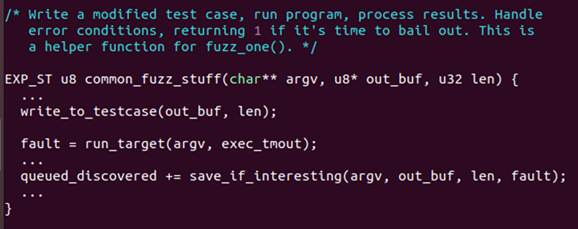
각 노드는 run_target()으로 Fuzzing을 수행한 후 그 결과를 보고
save_if_interesting() 함수를 통해 만약 흥미있는 Input일 경우(Coverage 증가 혹은 Crash 발생)
해당 Input값을 queue에 넣게 됩니다. (여기서 queue에 넣는다는 의미는
output directory의 queue directory 안에 input값을 파일로 저장한다는 의미입니다.)
※ common_fuzz_stuff() 함수의 경우 fuzz_one()의 핵심 helper 함수로서
fuzz_one()의 경우 Queue에서 하나의 입력(testcase)를 뽑아와서 Fuzzing하는
단일 작업 단위를 실행하는 함수입니다.
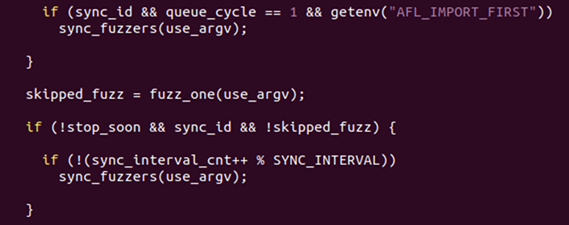
sync_fuzzers() 함수의 경우 보통 queue_cycle이 한번 다 돌거나
아니면 SYNC_INTERVAL이 된 경우 수행됩니다.
※ 여기서 sync_id 의 경우 위에서 봤던 fuzzer01과 같은 이런 fuzzer id입니다.
즉, single fuzzing의 경우 sync_id가 없습니다.
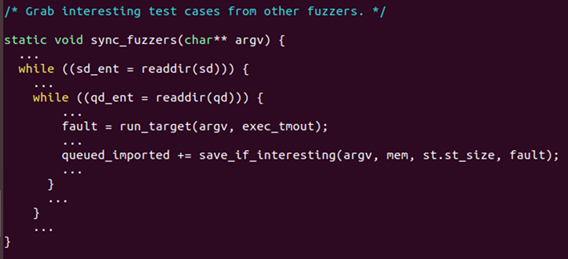
sync를 하는 과정은 다른 fuzzer의 output directory의 queue에 접근하여 새로운 input이 있을 경우 해당 input을 자신의 queue에 복사해오는 방식으로 진행됩니다.
AFL의 경우 많은 사람들이 사용하다보니 자료도 방대하여 원한다면 언제나 충분히 검색하여 공부할 수 있을 것 같습니다.
참고자료: https://aflplus.plus/docs/parallel_fuzzing/