LLM Wiki: 블로그 글을 살아있는 지식 베이스로 바꾸는 방법
LLM Wiki: 글을 읽고 끝내지 않고 계속 자라는 위키로 만들기
- 들어가며
- LLM Wiki는 뭐가 다른가?
- 핵심 구조: raw sources / wiki / schema
- 왜 그냥 RAG만으로는 아쉬웠나
- 이번에 잡은 구현 방식: Obsidian + AGENTS.md
- 직접 해보면서 느낀 점
- 마무리
들어가며
요즘은 LLM으로 문서를 읽고, 요약하고, 필요할 때 검색해서 답을 얻는 흐름이 꽤 익숙해졌습니다. 저도 예전에는 이런 방식이면 충분하지 않을까 생각했는데, 블로그 글이 조금씩 늘어나고 주제도 RAG, Agent Framework, CodeQL, MCP, 보안 분석 자동화처럼 서로 연결되는 방향으로 쌓이기 시작하니 단순 검색만으로는 조금 아쉽다는 생각이 들었습니다.
예를 들어 특정 질문을 할 때마다 관련 글을 다시 찾아야 하고, 서로 다른 포스트에 흩어진 개념들을 매번 새로 이어 붙여야 하고, 예전에 정리했던 내용과 최근에 정리한 내용을 사람이 직접 머릿속에서 합쳐야 했습니다. 검색은 되는데, 지식이 누적되는 느낌은 조금 약했던 것 같습니다.
그러다가 Andrej Karpathy가 올린 LLM Wiki 아이디어를 보고 꽤 흥미로웠습니다. 핵심은 "문서를 질문할 때마다 다시 읽는 방식"보다, LLM이 중간에 지속적으로 관리되는 위키 계층을 만들고 그 위키를 계속 업데이트하게 하자는 쪽에 더 가깝습니다.
이번에는 그 개념이 왜 괜찮아 보였는지 정리해보고,
실제로 제 블로그 글들을 raw source로 삼아
Obsidian 위에 작은 LLM Wiki를 만들어 본 경험도 같이 적어보려고 합니다.
LLM Wiki는 뭐가 다른가?
보통 문서 기반 LLM 활용이라고 하면 RAG를 먼저 떠올리게 됩니다. 파일을 넣어두고, 질문이 들어오면 관련 chunk를 찾고, 그걸 바탕으로 답을 만드는 구조 말입니다. 이 방식은 분명 유용합니다. 다만 질문이 들어올 때마다 LLM이 다시 관련 조각들을 찾고, 다시 읽고, 다시 조합해야 합니다.
그런데 자료가 계속 늘어나는 환경에서는 이 과정이 매번 처음부터 반복됩니다. 이전에 어떤 문서와 어떤 문서를 연결해서 봤는지, 어떤 개념이 이미 다른 글에서 설명되었는지, 최근에 추가된 자료가 예전 설명을 보완하는지 혹은 조금 수정해야 하는지 같은 것들이 대화가 끝나면 같이 사라지기 쉽습니다.
LLM Wiki 쪽은 발상이 조금 다릅니다. 원문을 그냥 색인만 해두는 것이 아니라, LLM이 그 내용을 읽고 개념 페이지, 프로젝트 페이지, 비교 페이지, 허브 문서로 다시 엮어 둡니다. 그러면 다음 질문부터는 raw source를 바로 뒤지는 대신, 이미 어느 정도 정리된 지식 계층을 먼저 읽고 들어갈 수 있습니다.
즉, 검색 결과를 그때그때 조합하는 구조에서 한 걸음 더 나아가 축적되는 중간 산출물을 만든다는 점이 제일 큰 차이로 느껴졌습니다. 질문에 대한 답도 결국은 사라지는 채팅 로그가 아니라, 필요하면 다시 위키 페이지로 편입될 수 있습니다.
핵심 구조: raw sources / wiki / schema
제가 이해한 LLM Wiki의 핵심 구조는 꽤 단순합니다. 크게 보면 원천 자료, 위키 본체, 운영 규칙 세 층으로 나눌 수 있습니다.
1. Raw sources: 원천 자료는 그대로 둔다
첫 번째 층은 raw source입니다. 블로그 글, 논문, 기사, 프로젝트 README, 이미지, 메모 같은 것들이 여기 들어갑니다. 중요한 점은 이 층은 읽기 전용으로 두는 것입니다. LLM이 이 파일들을 고치기 시작하면, 나중에는 뭐가 원문이고 뭐가 가공 결과인지 흐려지기 쉽습니다.
이번에 저는 이 raw source를
benjamin0326.github.io/_posts/에 있는 기존 블로그 글들로 잡았습니다.
필요할 때는 해당 글에서 설명하던 프로젝트 디렉터리도 보조 자료로 읽게 했고,
우선순위는 항상 블로그 글 쪽이 먼저 가도록 정리했습니다.
2. Wiki layer: LLM이 관리하는 지식 계층
두 번째 층은 실제 위키입니다.
여기에는 단순 요약만 있는 것이 아니라, 개념 페이지와 프로젝트 페이지, 비교 문서, 허브 문서가 같이 들어갑니다.
예를 들어 RAG 자체는 개념 페이지로,
lua-monologue는 프로젝트 페이지로,
RAG vs Rerank는 비교 문서로,
그리고 전체를 묶는 LLM Systems 같은 문서는 허브 페이지로 두는 식입니다.
이렇게 해두면 같은 개념이 여러 글에 반복해서 나오더라도 매번 긴 설명을 새로 쓰는 대신 한 곳으로 연결할 수 있습니다. 반대로 하나의 프로젝트도 "무슨 개념들과 묶여 있는지"를 위키 안에서 다시 볼 수 있습니다.
3. Schema: LLM을 위키 관리자로 만드는 문서
마지막 층이 의외로 제일 중요하다고 느꼈던 부분인데,
바로 AGENTS.md 같은 운영 규칙 문서입니다.
그냥 "위키를 잘 정리해줘"라고만 하면 매 세션마다 결과가 흔들리기 쉽습니다.
어떤 폴더에 어떤 문서를 만들지, 새 글이 들어오면 무엇을 먼저 갱신할지,
중복 페이지는 어떻게 피할지 같은 기준이 있어야 LLM이 일관되게 동작합니다.
저는 이 문서에 아래 같은 규칙들을 넣었습니다.
- raw source는 수정하지 말 것
- 위키는
Sources,Concepts,Projects,Maps같은 계층으로 나눌 것 - 새 글이 들어오면 source note를 만들고, 관련 concept / project / map 문서만 부분 갱신할 것
- 링크 없는 고립 문서를 양산하지 말 것
- 비슷한 이름의 중복 페이지보다 기존 페이지 갱신을 우선할 것
결국 이 schema 문서가 있어야 LLM이 그냥 대답 잘하는 챗봇이 아니라, 꽤 성실한 위키 관리자로 바뀌는 느낌이었습니다.
왜 그냥 RAG만으로는 아쉬웠나
사실 저도 RAG 자체는 여전히 꽤 유용하다고 생각합니다. 예전에도 RAG + Rerank를 다루면서 retrieval이 얼마나 중요한지 정리한 적이 있습니다. 그리고 코드 분석 쪽으로 가면 단순 chunk retrieval만으로는 부족해서 CodeQL이나 구조 파서, 혹은 에이전트 기반 접근이 같이 붙기도 합니다.
다만 개인 지식 베이스 관점에서는 질문 시점마다 다시 검색해서 조합하는 구조보다, "이미 어느 정도 구조화되어 있는 markdown 위키"를 두는 편이 훨씬 덜 피곤해 보였습니다. 특히 제가 이미 블로그에 정리한 내용들은 개별 글로는 괜찮지만, 시간이 지나면 서로의 연결관계가 점점 더 중요해집니다.
예를 들어
RAG는 retrieval 구조 쪽으로,
CrewAI는 multi-agent orchestration 쪽으로,
secure-code-auditor는 로컬 LLM + MCP 스타일 도구 호출 쪽으로 이어지는데,
이런 것들을 그냥 파일 검색으로만 따라가면 계속 "다시 읽기"를 해야 합니다.
반면 위키 계층이 있으면 이미 정리된 개념 페이지를 먼저 읽고, 부족한 부분만 raw source로 내려가면 됩니다.
즉, RAG가 질문 시점의 검색 문제를 잘 푼다면, LLM Wiki는 지식 유지보수 문제를 좀 더 잘 푼다는 느낌이었습니다.
이번에 잡은 구현 방식: Obsidian + AGENTS.md
이번에는 이 아이디어를 아주 거창하게 서비스로 만든 것은 아니고,
로컬에서 Obsidian Vault를 하나 두고 그 위에 LLM이 markdown 문서를 관리하는 방식으로 먼저 잡아보았습니다.
개인적으로는 이 조합이 꽤 마음에 들었습니다.
Obsidian은 링크와 graph view를 확인하기 좋고,
LLM은 문서를 쓰고 수정하고 연결하는 쪽에 강하니까 역할 분담이 자연스럽습니다.
제가 만든 Vault의 목적은 간단합니다.
_posts에 있는 기존 블로그 글들을 raw source로 두고,
그 위에 LLM이 개념 문서와 프로젝트 문서, 허브 문서를 계속 쌓아가게 하는 것입니다.
그리고 이때 어떤 파일을 만들고 어떻게 갱신할지는
Vault 안의 AGENTS.md가 기준이 되도록 했습니다.
현재 Vault 구조
현재는 아래와 같은 식으로 구조를 잡아두었습니다. 아직 작은 규모이지만, 개념적으로는 이 정도만 있어도 꽤 잘 굴러가는 것 같습니다.
llm_wiki_benjamin/
├── AGENTS.md
├── Home.md
├── Index.md
├── Log.md
├── Sources/
│ └── Posts/
│ ├── 2025-07-13-RAG_Rerank.md
│ ├── 2025-07-21-CodeQL.md
│ ├── 2025-08-30-CrewAI_Security_Project.md
│ ├── 2025-12-14-Security_Brief.md
│ └── 2026-02-24-secure-code-auditor.md
├── Concepts/
│ ├── Agent.md
│ ├── Agent Security.md
│ ├── CodeQL.md
│ ├── CrewAI.md
│ ├── MCP.md
│ ├── RAG.md
│ ├── Reporting Transparency.md
│ ├── Rerank.md
│ └── Tree-sitter.md
├── Projects/
│ ├── crew_security_project.md
│ ├── lua-monologue.md
│ └── secure-code-auditor.md
├── Maps/
│ ├── Agent Frameworks.md
│ ├── LLM Systems.md
│ └── Security Analysis with LLMs.md
└── Comparisons/
└── RAG vs Rerank.md
여기서 Sources/Posts는 원문을 다시 쓰는 곳이 아니라,
각 글에서 무엇을 추출했고 어떤 문서에 반영했는지 기록하는 source note 역할을 합니다.
Concepts는 반복 등장하는 개념을 한 군데로 모으는 곳이고,
Projects는 로컬 프로젝트나 사이드 프로젝트를 개념과 연결하는 층입니다.
Maps는 말 그대로 허브 역할을 합니다.
개인적으로는 이 Maps 문서들이 꽤 중요하다고 느꼈습니다.
페이지 수가 조금만 늘어나도 "무엇을 먼저 읽어야 하지?"가 생기는데,
허브 문서 하나만 잘 잡아도 위키 전체의 진입점이 훨씬 좋아집니다.
운영 흐름: ingest / update / query
운영 흐름도 최대한 단순하게 잡았습니다.
_posts/*.html
↓
source note 생성
↓
Concepts / Projects / Maps 관련 문서 갱신
↓
Index.md / Log.md 갱신
↓
다음 질문부터는 raw source 대신 위키 계층을 먼저 탐색
- Ingest: 새 블로그 글이나 자료가 들어오면 source note를 만든다.
- Update: 관련된 개념 페이지, 프로젝트 페이지, 허브 문서만 부분 갱신한다.
- Query: 질문이 들어오면 raw source를 처음부터 다 뒤지기보다, 먼저 위키 계층을 읽고 부족한 부분만 추가로 본다.
그리고 별도로 Index.md와 Log.md를 두었습니다.
Index는 현재 어떤 문서가 있는지 빠르게 찾기 위한 파일이고,
Log는 언제 무엇을 추가하고 수정했는지 남기는 append-only 기록입니다.
생각보다 이런 파일이 있어야 LLM도 덜 헤매고, 저도 최근 변경사항을 따라가기 쉬웠습니다.
나중에 문서 수가 더 많아지면 검색 도구나 Dataview 같은 것을 붙일 수도 있겠지만, 지금 규모에서는 markdown 파일과 index만으로도 충분히 시작할 수 있을 것 같습니다.
직접 해보면서 느낀 점
아직은 초기 단계라서 "와 이제 완벽한 지식 베이스가 생겼다" 수준은 아닙니다. 다만 생각보다 괜찮았던 점은, 이 구조가 블로그 글을 단순 아카이브에서 서로 연결된 지식 그래프 비슷한 형태로 바꿔준다는 것이었습니다.
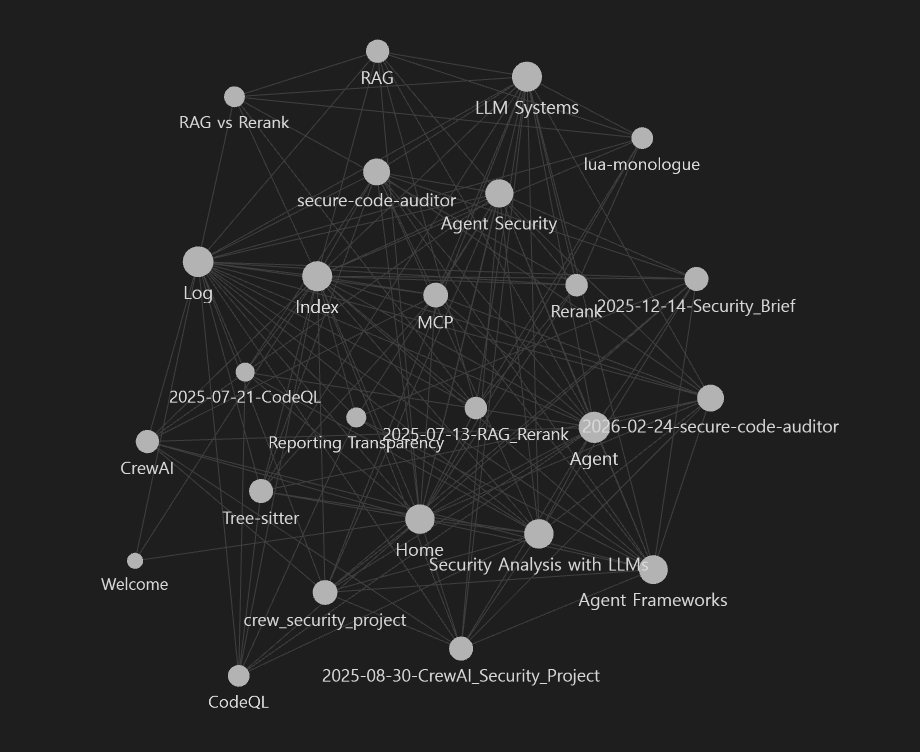
예전에는 포스트가 늘어날수록 검색은 가능해도 연결은 사람이 담당해야 했습니다. 그런데 위키 계층이 하나 생기니, 예전에 쓴 글이 최근 글의 배경지식이 되고, 프로젝트 설명이 다시 개념 페이지로 올라가고, 질문하다가 나온 비교 정리도 새 문서로 남길 수 있게 되었습니다. 이 지점이 생각보다 꽤 컸습니다.
실제로 graph view를 보면 Home, Index, Log 같은 운영 문서와
RAG, Agent, MCP, CodeQL 같은 개념 문서들이
허브처럼 묶이기 시작한 것을 확인할 수 있습니다.
아직 규모는 작지만, 적어도 글이 따로 흩어져 있는 아카이브보다는
"서로 연결된 위키" 쪽에 더 가까워졌다는 점이 꽤 마음에 들었습니다.
또 하나 느낀 점은, 이 구조에서는 LLM의 역할이 "정답을 한 번 잘 말해주는 것"보다 꾸준히 정리하고 링크를 유지하는 것에 더 가까워진다는 점입니다. 이 부분은 사람이 하기엔 은근 귀찮고 반복적인데, LLM은 이런 bookkeeping에는 꽤 잘 맞는 것 같습니다.
반대로 아직 아쉬운 부분도 있습니다.
예를 들어 어떤 개념을 독립 페이지로 승격할지, 어느 정도까지 자세히 써야 할지,
기존 설명을 언제 업데이트해야 할지는 schema가 조금만 부실해도 결과가 흔들릴 수 있습니다.
결국 위키 품질은 모델 성능만큼이나 AGENTS.md 같은 운영 문서 품질에도 크게 영향을 받는 것 같습니다.
마무리
이번에 LLM Wiki를 직접 조금 만져보면서 느낀 건, 이게 단순히 "Obsidian에 문서 많이 넣기"가 아니라 LLM이 계속 유지보수하는 중간 지식 계층을 만드는 작업이라는 점이었습니다.
개인적으로는 이미 블로그나 메모, 프로젝트 문서가 조금씩 쌓여 있는 사람에게 꽤 잘 맞는 방식이라고 생각합니다. raw source는 그대로 두고, 그 위에 개념/프로젝트/비교 문서를 계속 덧대는 구조라서 시간이 지날수록 "다시 읽는 비용"을 조금씩 줄여줄 수 있기 때문입니다.
이번 글에서는 개념 자체와 현재 잡아본 구현 방향 위주로만 적어보았는데, 다음에는 실제로 새 포스트가 들어왔을 때 어떤 문서들이 갱신되는지, Obsidian graph view에서 어떤 식으로 클러스터가 생기는지, 그리고 이 구조에 search나 MCP tool을 붙이면 어디까지 편해질 수 있을지도 한 번 더 정리해보면 좋을 것 같습니다.